triplet训练和对比学习有什么不同?区别在这儿一文读懂!

今天咱们来聊聊Triplet训练和对比学习,这俩家伙名字听着有点绕,但它们都是搞定样本之间相似度关系的“高手”。我最近在搞一个图文匹配的项目,一开始光听说名字就犯怵,琢...
今天咱们来聊聊Triplet训练和对比学习,这俩家伙名字听着有点绕,但它们都是搞定样本之间相似度关系的“高手”。我最近在搞一个图文匹配的项目,一开始光听说名字就犯怵,琢磨着这到底有啥区别,折腾了好一阵子,现在算是有点眉目了,赶紧跟大家伙儿唠唠我的实践体会。
我这项目是想让系统学会“这张图应该配上哪段文字”,说白了,就是要算相似度嘛最开始我琢磨着能不能直接用交叉熵什么的,结果效果很拉胯,因为标注数据太少了,模型根本学不会什么叫“像”什么叫“不像”。
先说Triplet训练是怎么玩的。
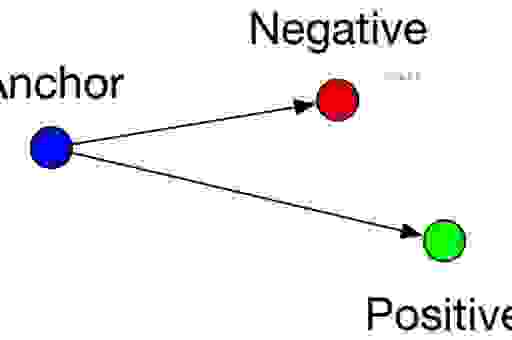
我一开始就上手试了Triplet Loss。这个东西的核心思想就是拉近“锚点”(Anchor)和“正样本”(Positive)的距离,同时推远“锚点”和“负样本”(Negative)的距离。我得先构造出这种三元组来。
- 我找来一批图片,随便选一个当锚点A。
- 我得找一张和A“应该”配对的文字描述B,B就是正样本P。
- 我得找一段和A“完全不搭界”的文字描述C,C就是负样本N。
构造完这组(A, P, N)之后,我就把它们一起丢进网络里跑一遍,算出它们的嵌入向量。然后,我得套用那个公式:$Distance(A, P) + Margin < Distance(A, N)$。Margin(边距)这个参数特别关键,我一开始图省事设得小了,结果A、P、N挤在一块儿,分不清楚。后来我把Margin调大点,比如0.5,效果才明显起来,负样本真的被推得离锚点更远了。
接着说说对比学习,这套路就稍微有点不一样了。
我发现对比学习(Contrastive Learning)更侧重于“数据增强”和“自监督”。在我的图文项目里,我没有那么多现成的正负样本对,所以我得自己“创造”出来。
我干的第一件事就是对每张图片做两遍不同的数据增强(比如随机裁剪、颜色抖动、翻转什么的),这样我就得到了同一张图的两个“视图”,这两个视图就是一对“正样本”。

然后,我用一个Encoder(比如一个Transformer)把这两个视图都编码成向量。对比学习的目标就是让这两个视图的向量靠得越近越
“负样本”?负样本就是当前Batch里所有其他样本的向量。我得想办法让当前正样本对的向量远离其他所有负样本的向量。我用的是InfoNCE Loss,它本质上就是在最大化正样本对与其他负样本之间的互信息。
到底有啥区别?
我总结了一下我的实践感受,这俩核心差异就在于数据构造和训练目标上。
Triplet训练是“明确”地告诉你,A和B要近,A和C要远。你必须事先知道哪些是正,哪些是负,才能构造出三元组。它是在一个固定的局部结构里优化距离关系。
对比学习,它更像是在一个全局的视角里学习特征表示。它不依赖外部标签,而是自己通过数据增强构建正样本对,然后让这些在潜在空间里“靠得近”的样本具有相似的特征。我的体会是,对比学习出来的特征空间更鲁棒,因为你给模型看了同一个东西的不同侧面。
在我的项目里,Triplet训练需要我手动或者靠规则去挑选负样本,这很难控制质量,万一负样本不够“负”,训练就白搭了。而对比学习,尤其是在没有标签的情况下,通过数据增强自动生成高质量的正样本对,让模型学会抓住“本质特征”,而不是表层噪声。
我现在这个项目,还是采用了对比学习的框架,因为它在特征表示的学习上更胜一筹,虽然训练初期需要花大力气调数据增强的策略,但一旦跑起来,得到的特征向量质量真的高很多,后面再接一个简单的线性层做分类或者匹配,效果就立竿见影了。